Chinese MNIST Classification 1 — data preparation
data: https://www.kaggle.com/gpreda/chinese-mnist

import pandas as pd
dataframe = pd.read_csv('./chinese_mnist.csv')
inspect the dataset
dataframe.columns
Index(['suite_id', 'sample_id', 'code', 'value', 'character'], dtype='object')check balance
dataframe.groupby(["value","character"]).size()

checking the missing data
def missing_data(data):
null_total = data.isnull().sum().sort_values(ascending = False)
null_percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
data_miss = pd.concat([null_total, null_percent], axis=1, keys=['Total', 'Percent'])
return data_miss
Check the duplicated


suite_id,sample_id,code is used to generate the image file name. so we can use these columns to generate image name
filename_1='suite_id'
filename_2='sample_id'
filename_3='code'
filename=f'{os.getcwd()}/data/input_{dataframe.iloc[0][filename_1]}_{dataframe.iloc[0][filename_2]}_{dataframe.iloc[0][filename_3]}.jpg'let’s check the first file name that generated. os.getcwd() is to get current directory.

let’s define a function to generate image. we also read image list into numpy.
def generate_image_array_from_file(imgArray,dataframe):
for i in range (dataframe.shape[0]):
filename=f'{os.getcwd()}/data/input_{dataframe.iloc[i][filename_1]}_{dataframe.iloc[i][filename_2]}_{dataframe.iloc[i][filename_3]}.jpg'
img=cv2.imread(filename,0)
#or you can read image via
#img=skimage.io.imread(filename) imgArray.append(img)
return np.array(imgArray)myImgArray=[]
myImgArray=generate_image_array_from_file(myImgArray,dataframe)
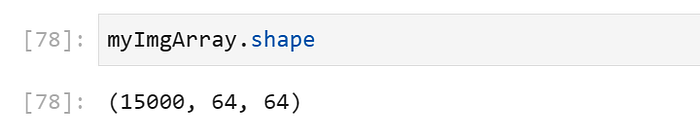
we get an numpy array with input shape = 15000,64,64.
Check the image
for i in range(3):
plt.imshow(myImgArray[np.random.randint(0,12000)],cmap='Greys')
plt.show()
if you do not want use for loop to generate image array. you can use python apply function instead. first we need add a column to dataframe to indicate the filename location. then we apply read_image function to it.
def read_image(filename):
#img=cv2.imread(filename,0)
image=skimage.io.imread(filename)
return image
def create_file_name(x):
file_name = f'{os.getcwd()}/data/input_{x[0]}_{x[1]}_{x[2]}.jpg'
return file_namedataframe['filename'] = dataframe.apply(create_file_name,axis=1)
myImgArray=np.stack(dataframe['filename'].apply(read_image))
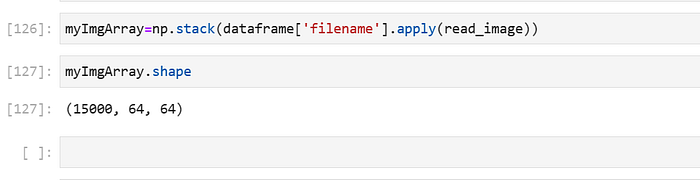
Here we use numpy np.stack to stack the image.
scale the pixel value between 0 and 1
nparrayscaled=myImgArray/255So far ,we got an image array with input = 15000,64,64, and all pixel value is between 0 and 1
plot one diagram for each class
we get y value from cloumn ‘code’
y=dataframe['code']).to_numpy()for i,j in enumerate(np.unique(y)*1000):
plt.subplot(3,5,i+1)
plt.imshow(myImgArray[j-1])
plt.title(‘class’+str(y[j-1]))
plt.show()
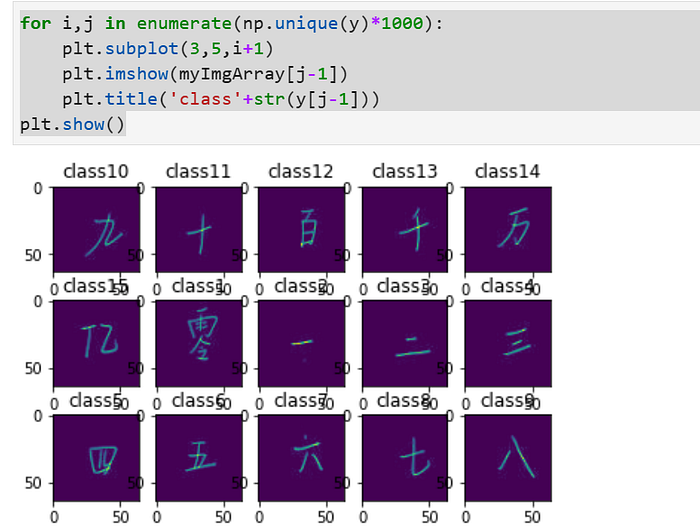
get y value from
datafram
Y value will be the class for each chareacter . we need to use one -hot coding. there are multple ways to do that. the simplest one is use pandas get dummy function.
y=pd.get_dummies(dataframe['code']).to_numpy()or use
y2 = dataframe['code'].to_numpy()
le = LabelEncoder()
y2_enc = le.fit_transform(y2)
np.unique(y2)
y2= to_categorical(y2_enc)the result will be same
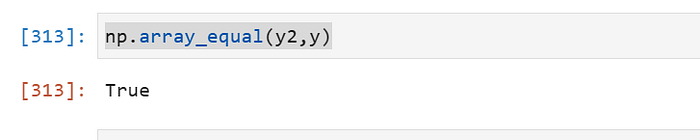
after one hot encoding. each class value can be obtained by use argmax
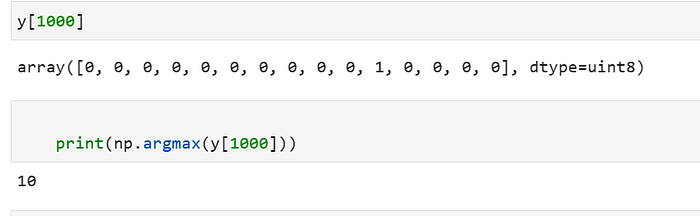
So far, we get image array which in format numpy (15000,64,64) and Y which already in one hot coding.
